我把民事诉讼律师蒸馏了

一、从”让机器人拿一杯水”说起

想象你对一个机器人说:”去厨房给我拿一杯水。”
如果这是一个足够聪明的机器人,它可能会转身走向厨房;但如果它不够聪明,你很可能会看到它在客厅里原地打转——因为它不知道”厨房在哪””杯子在哪””水从哪来””接多少算一杯””怎么端过来才不会洒”。
人类的大脑会自动补全这些子任务:找到厨房 → 找到干净的杯子 → 确认水源 → 接适量的水 → 平稳地端回来。但机器不会。你必须把任务切分成明确的步骤,给每一步定义清晰的输入、输出和判断标准,机器才有可能完成。
这就是任务切分思维(Task Decomposition)。它是人工智能领域的一个基础命题,却很少有人把它真正应用到法律实务中。
过去两年,自从 ChatGPT 掀起生成式 AI 的浪潮,法律行业涌现了大量的”AI 使用指南”。但恕我直言,绝大多数都停留在同一个层面——“如何让 AI 帮我写一份起诉状””如何用 AI 做类案检索”。这些工具当然有用,但它们解决的问题,就像是教会了机器人”如何找到杯子”,却没有告诉它”杯子找到之后该怎么办”。
如果你对一个 AI 说”帮我打个官司”,它大概率会失败。不是因为 AI 不够聪明,而是因为”打官司”这个任务没有被切分成机器可执行的步骤序列。
于是我开始思考:如果把民事诉讼律师的办案思维,像”拿一杯水”一样逐层切分、定义输入输出、明确判断标准,最后蒸馏成一套 AI 可协作执行的全流程 SOP,会发生什么?
这个项目,就是我对这个问题的回答。
二、项目定位:这不是模板包,而是一次”任务蒸馏”

在介绍具体功能之前,我想先澄清一个常见的误解。
市面上很多法律 AI 产品提供的是”一键生成诉状””一键生成答辩状”的功能。这些工具当然能节省时间,但诉讼实务远不止一份诉状。从接案到归档,一个标准的民事诉讼案件通常要经历数十个关键节点:收集材料、整理事实、确定策略、起草文书、编排证据、质证交锋、庭审应对、庭后补充、上诉研判、申请执行、结案归档……每一个节点都有专业的判断空间,也都有出错的风险。
本项目要做的,不是给律师一个”诉状生成器”,而是把”打一场官司”这个复杂任务,蒸馏成一套结构化、阶段化、可迭代的 AI 协作工作流。
所谓”蒸馏”,是一个借自化学和机器学习的概念。它的意思是:把原本混杂在大量信息中的核心要素,通过逐层提纯,萃取成高浓度、可复用的精华。放在本项目里,就是把民事诉讼律师头脑中的隐性知识(tacit knowledge)——那些”know-how”层面的办案直觉、阶段判断、风险嗅觉——通过任务切分、角色定义、输入输出标准化,萃取成显性可执行的流程。
22 份参考模板只是这个工作流的载体。真正的价值在于阶段间的数据流转和思维框架。用一句话概括区别:模板库是静态的,它给你一条鱼;工作流是动态的,它教你捕鱼,还教你怎么判断鱼是否新鲜。
三、设计思维:如何把”打一场官司”切分成机器可执行的步骤?

这是全文最核心的章节。我要详细展开任务切分思维在诉讼场景中的应用,以及这个项目是如何一步步搭建起来的。
3.1 第一层切分:把诉讼切成四个”大阶段”
最粗糙的切分方式是按”文书类型”——诉状、答辩状、证据清单、代理词……但这种方式忽略了一个关键变量:时间。
诉讼是一个在时间轴上展开的过程,每个阶段都有不可逆的决策节点。错过举证期限,可能导致关键证据失权;错过上诉期限,可能导致一审判决生效。因此,本项目的第一层切分,是按**”诉讼时间轴 + 决策节点”**来划分:
- 战略备战(接案 → 确定策略):这是诉讼的”输入端”。在这个阶段,律师需要把客户提供的原始材料(合同、聊天记录、转账凭证等)转化为结构化信息,识别缺失证据,制定攻防策略。
- 起诉应诉及证据工作(策略 → 正式文书):把第一阶段梳理的事实和策略,转化为可直接提交法院的起诉状、答辩状、证据目录、证据说明等正式文件。
- 庭前交锋(文书 → 庭审):在正式开庭前,针对对方提交的材料进行质证分析,制定庭审预案,预测争议焦点。
- 裁决与执行(庭审 → 结案):庭后代理词的撰写、上诉或应诉的研判、强制执行程序的启动、以及最终的结案归档。
切分的原则是:每一个阶段的输出物,必须是下一个阶段的输入物。 战略备战的”案件事实时间轴”,流入起诉应诉阶段成为起诉状的事实基础;起诉应诉阶段的”证据目录”,流入庭前交锋阶段成为质证意见的审查对象;庭前交锋阶段的”庭审摘要”,流入裁决执行阶段成为代理词或上诉状的素材来源。
这种设计形成了一个数据闭环,避免了传统办案中常见的”信息断层”问题。
3.2 第二层切分:每个阶段再切成”可执行的步骤”
以”战略备战”阶段为例,如果仅仅告诉 AI”请帮我做战略备战”,它大概率会输出一堆泛泛而谈的建议。你需要继续切分:
- Step 0:收集原始材料,列出材料清单,识别缺失信息
- Step 1:按时间顺序整理案件事实,生成”案件事实时间轴”
- Step 2:基于已整理的事实,进行类案检索框架搭建
- Step 3:根据当事人角色(原告/被告),制定诉讼方案或应诉方案
每一步都有明确的输入(需要什么材料)、输出(生成什么文件)、判断标准(怎样算完成)。例如,”案件事实时间轴”的完成标准是:每一个关键事件都有日期、有内容摘要、有对应证据、有争议标注。达不到这个标准,就不能进入下一步。
3.3 第三层切分:给 AI 写”岗位说明书”
任务切分到步骤层面还不够。人脑中有大量的”默认假设”——律师知道”起诉状的事实部分要和证据一一对应””质证意见要区分真实性、合法性、关联性””提交法院的版本不能有攻击性措辞”——但 AI 不知道。你必须把这些默认假设显式化。
这就是 SKILL.md 的设计逻辑。
在本项目中,每一个阶段都配备了三类文件:
- README.md:给人类看的阶段说明书,解释这个阶段做什么、为什么做、怎么做。
- SKILL.md:给 AI 看的”岗位说明书”,定义 AI 在这个阶段扮演什么角色、遵循什么格式、什么必须做、什么绝对不能做。
- 参考模板:可直接套用的 Markdown 文件,供 AI 和人类参考格式。
SKILL.md 不是使用教程,而是工作指令。它的写法类似于给新员工写岗位 JD:”你的职责是整理案件事实时间轴;你必须按时间顺序排列;每一个事件必须标注对应证据;你不能对事实进行法律评价;你不能删除原始材料。”
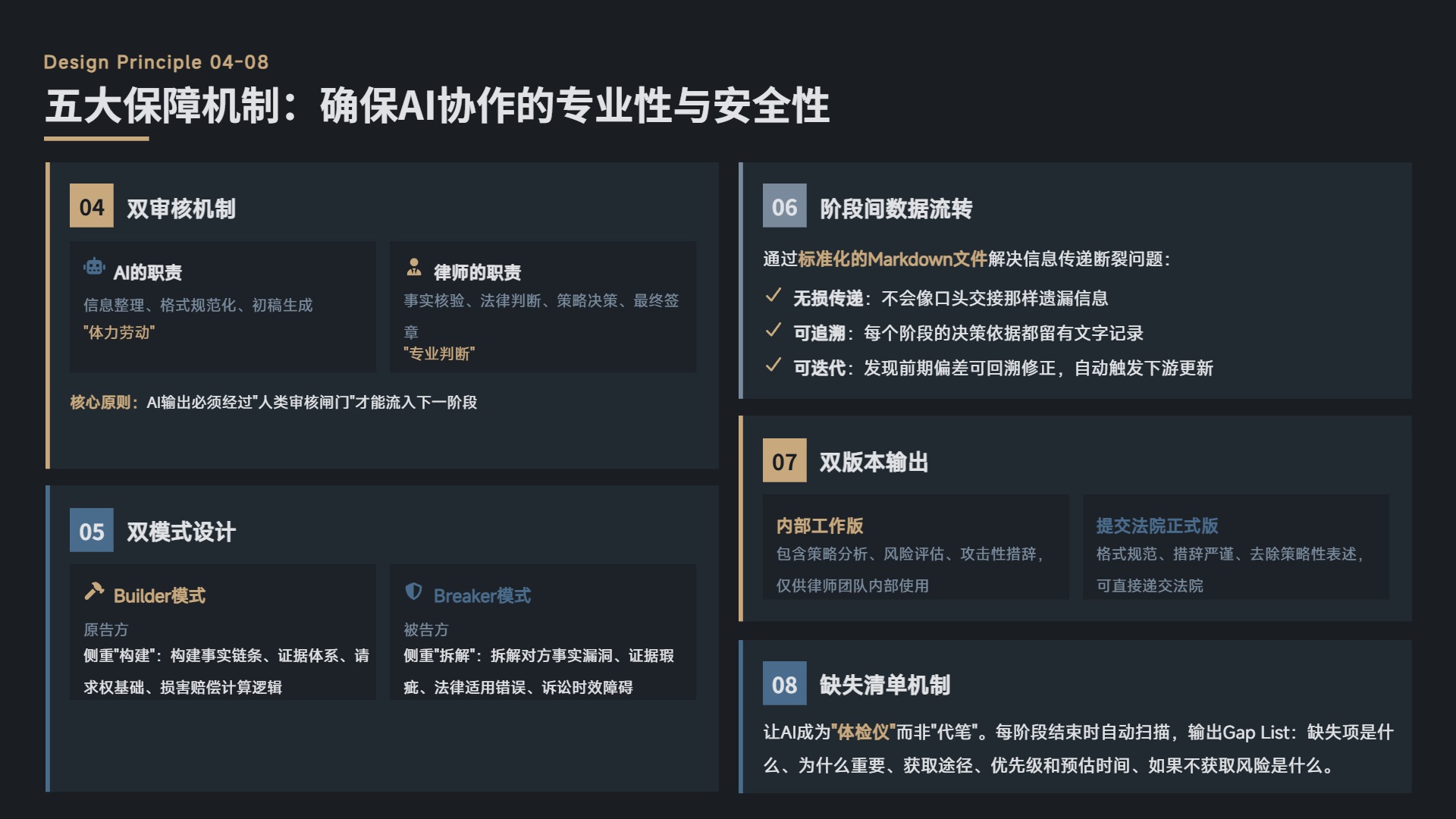
3.4 双审核机制:AI 是”助理”,律师是”负责人”
我在之前的文章《给律师同行的 ChatGPT 类生成式大模型使用建议》中,专门讨论过生成式 AI 的”机器幻觉”问题——AI 会基于概率生成看起来合理但实际上错误的内容,而且它会一本正经地胡说八道。
这个风险在诉讼实务中是致命的。一份写错法律条款的起诉状、一份遗漏关键证据的证据目录、一份事实陈述自相矛盾的代理词,都可能导致当事人的实体权利受损。
因此,本项目从设计之初就确立了双审核机制:
- AI 的职责:承担信息整理、格式规范化、初稿生成的”体力劳动”。
- 律师的职责:承担事实核验、法律判断、策略决策、最终签章的”专业判断”。
每一套 SKILL.md 中都内置了明确的边界提示:”AI 生成的是初稿,需经具备执业资格的专业人士审核、修改、签章后方可提交法院。”这不是免责声明,而是工作流的核心节点——AI 的输出必须经过一个”人类审核闸门”,才能流入下一阶段。
3.5 双模式设计:原告(Builder)与被告(Breaker)视角
诉讼是对抗性的。一个只会进攻的律师不是好律师,一个只会防守的律师同样不是好律师。但现实中,很多年轻律师由于执业初期的案源结构,往往只熟悉某一类角色——比如长期做银行金融案件的律师,可能只做过原告代理人,对被告方的抗辩思路相对陌生。
本项目在每个阶段都设计了双模式:
- Builder 模式(原告方):侧重于”构建”。构建事实链条、构建证据体系、构建请求权基础、构建损害赔偿计算逻辑。
- Breaker 模式(被告方):侧重于”拆解”。拆解对方事实漏洞、拆解证据瑕疵、拆解法律适用错误、拆解诉讼时效障碍。
这不是简单地把”原告”换成”被告”的文字游戏。两种模式下的任务切分、关注重点、输出格式都有本质差异。例如,在战略备战阶段,Builder 模式会引导 AI 寻找”对方违约/侵权的确定性事实”,而 Breaker 模式会引导 AI 寻找”我方行为具有正当性的抗辩空间”。
3.6 阶段间数据流转:让信息像流水一样传递
传统诉讼中,信息传递的断裂是一个常见问题。接案律师可能口头交代几句就转交给出庭律师;出庭律师开完庭写个便签就交给执行律师;执行律师发现关键证据没调、财产线索没查,但案件已经错过了最佳执行时机。
本项目通过标准化的 Markdown 文件来解决这个问题。每一个阶段的产出都是结构化的文本文件,下一个阶段的 AI 可以直接读取、解析、引用。这种设计有几个好处:
- 无损传递:不会像口头交接那样遗漏信息。
- 可追溯:每一个阶段的决策依据都留有文字记录。
- 可迭代:如果后续发现前期事实整理有偏差,可以回溯到源头修正,并自动触发下游更新。
3.7 双版本输出:内部工作版 vs 提交法院正式版
诉讼实务中有一个微妙的区别:律师内部讨论时使用的文件,和提交给法院的文件,往往不是同一个版本。
内部工作版可以写:”对方提交的这份聊天记录真实性高度存疑,很可能是事后伪造的,建议申请鉴定。”
提交法院版则要写:”对证据 X 的真实性持有异议。该证据系电子数据,对方未提供原始载体,亦未证明其完整性,申请法院委托鉴定机构对其真实性进行鉴定。”
本项目在关键节点(如证据说明、质证意见)设计了双版本输出:
- 内部工作版:包含策略分析、风险评估、攻击性措辞,仅供律师团队内部使用。
- 提交法院正式版:格式规范、措辞严谨、去除策略性表述,可直接递交法院。
两个版本由同一份源材料生成,但由不同的输出规则控制,避免了”把内部讨论稿误交法院”的尴尬。
3.8 缺失清单机制:让 AI 成为”体检仪”而非”代笔”
大多数法律 AI 工具的使用场景是:你把材料丢给它,让它”写一份起诉状”。但如果你的材料本来就不全呢?如果关键证据缺失、重要事实不清、对方身份信息不明呢?
这些工具通常不会告诉你”还缺什么”,它们只会基于已有材料生成一份看起来完整但实际上有漏洞的文书。
本项目在每一阶段结束时,都设置了缺失清单(Gap List)机制。AI 会自动扫描已收集的材料和已完成的任务,输出一份清单:
- 缺失项是什么?
- 为什么重要?
- 获取途径有哪些?
- 优先级和预估时间?
- 如果不获取,风险是什么?
这个设计的目的是让 AI 成为一台”体检仪”——在病症恶化之前就发现病灶,而不是等到开庭前才手忙脚乱地补材料。
四、四大阶段功能全景图

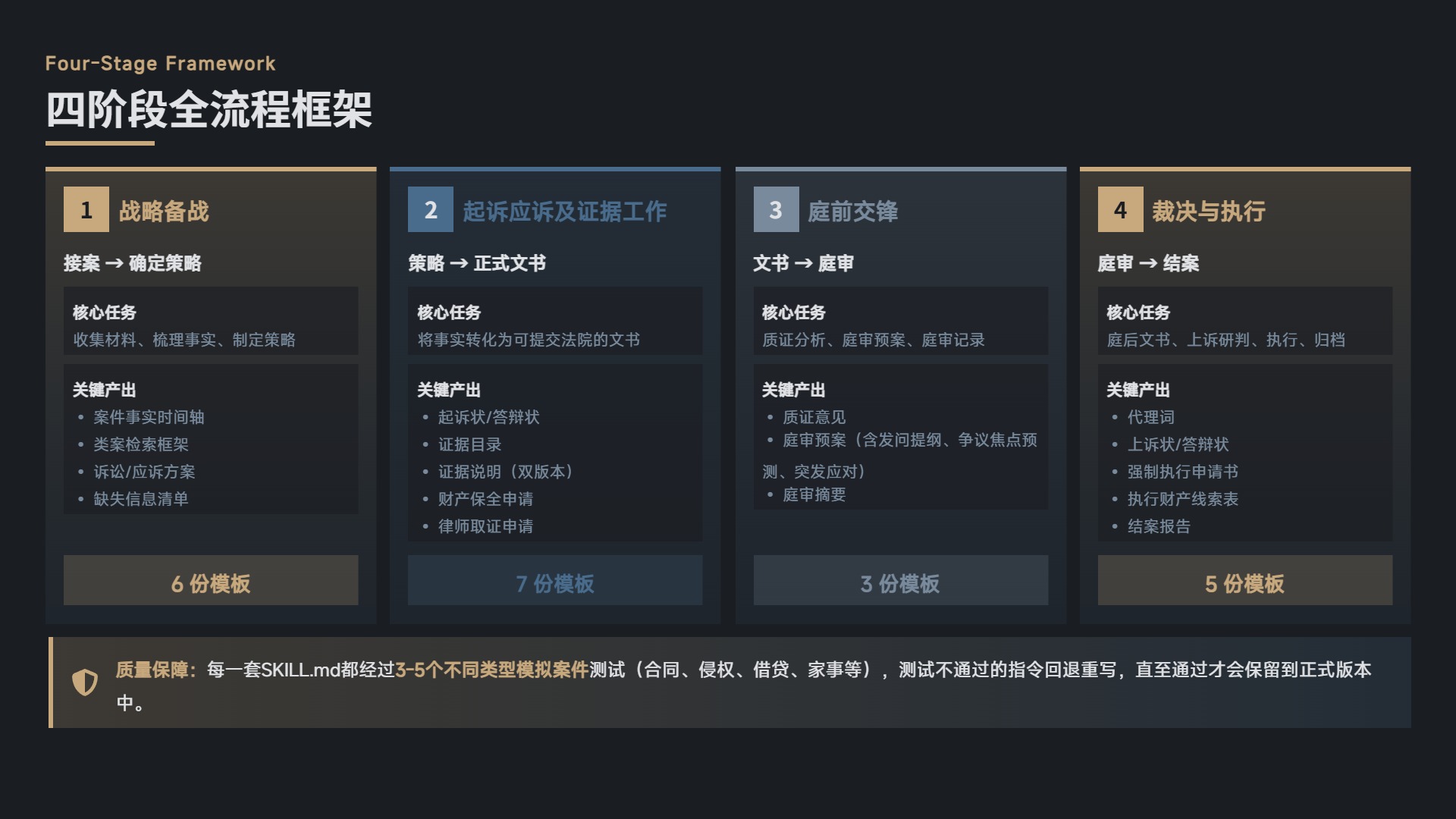
经过上述的任务切分和蒸馏,最终形成了四个阶段、二十余个标准步骤、22 份参考模板的全流程框架。
| 阶段 | 核心任务 | 关键产出 | 参考模板数 |
|---|---|---|---|
| 阶段一:战略备战 | 收集材料、梳理事实、制定策略 | 案件事实时间轴、类案检索框架、诉讼/应诉方案、缺失信息清单 | 6 份 |
| 阶段二:起诉应诉及证据工作 | 将事实转化为可提交法院的文书 | 起诉状/答辩状、证据目录、证据说明(双版本)、财产保全申请、律师取证申请 | 7 份 |
| 阶段三:庭前交锋 | 质证分析、庭审预案、庭审记录 | 质证意见、庭审预案(含发问提纲、争议焦点预测、突发应对)、庭审摘要 | 3 份 |
| 阶段四:裁决与执行 | 庭后文书、上诉研判、执行、归档 | 代理词、上诉状/答辩状、强制执行申请书、执行财产线索表、结案报告 | 5 份 |
需要特别强调的是:每一套 SKILL.md 都不是凭空写的。在开发过程中,笔者为每个阶段设计了 3~5 个不同类型的模拟案件——包括合同纠纷、民间借贷、侵权责任、离婚财产分割等常见案由——用 AI 生成虚拟的原始材料(合同文本、聊天记录、转账凭证等),输入到 SKILL.md 中,检验 AI 的产出是否符合预期格式、逻辑是否自洽、是否遗漏关键信息。
测试不通过的 SKILL.md 会被回退修改,直至通过测试才会被保留到正式版本中。 这是保证项目”基础可用性”的核心手段。当然,模拟案例测试无法替代真实案件的复杂性和突发状况,但它至少确保了这套工作流在”标准场景”下不会出结构性错误。
五、三种典型办案场景的 workflow

为了更直观地展示这个项目怎么用,以下用三个场景来说明。
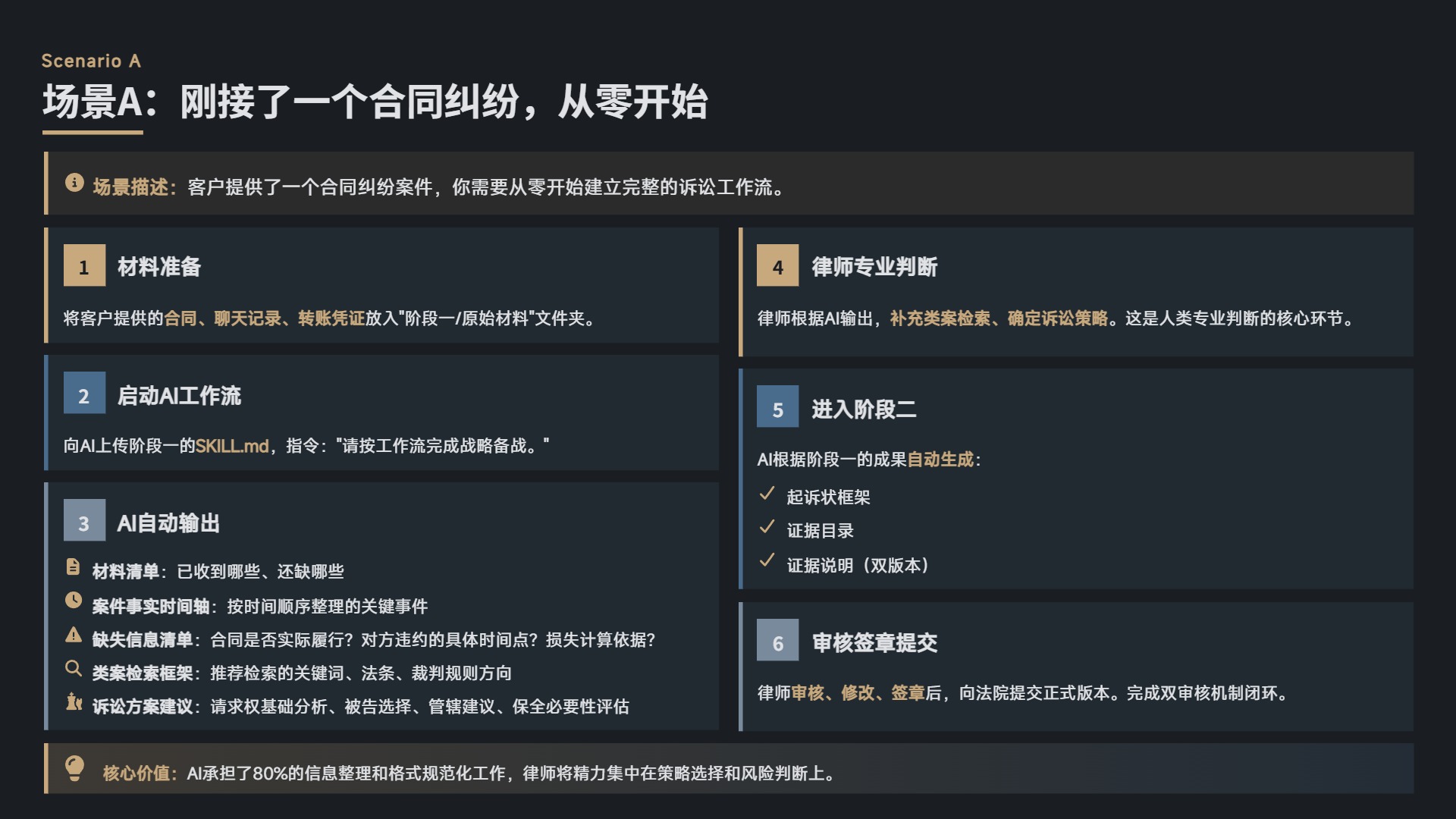
场景 A:刚接了一个合同纠纷,从零开始
- 将客户提供的合同、聊天记录、转账凭证放入”阶段一/原始材料”文件夹。
- 向 AI 上传阶段一的 SKILL.md,指令:”请按工作流完成战略备战。”
- AI 读取材料后,输出:
- 材料清单(已收到哪些、还缺哪些)
- 案件事实时间轴(按时间顺序整理的关键事件)
- 缺失信息清单(如:合同是否实际履行?对方违约的具体时间点?损失计算依据?)
- 类案检索框架(推荐检索的关键词、法条、裁判规则方向)
- 诉讼方案建议(请求权基础分析、被告选择、管辖建议、保全必要性评估)
- 律师根据 AI 输出,补充类案检索、确定诉讼策略。
- 进入阶段二,AI 根据阶段一的成果自动生成起诉状框架、证据目录、证据说明(双版本)。
- 律师审核、修改、签章后,向法院提交正式版本。
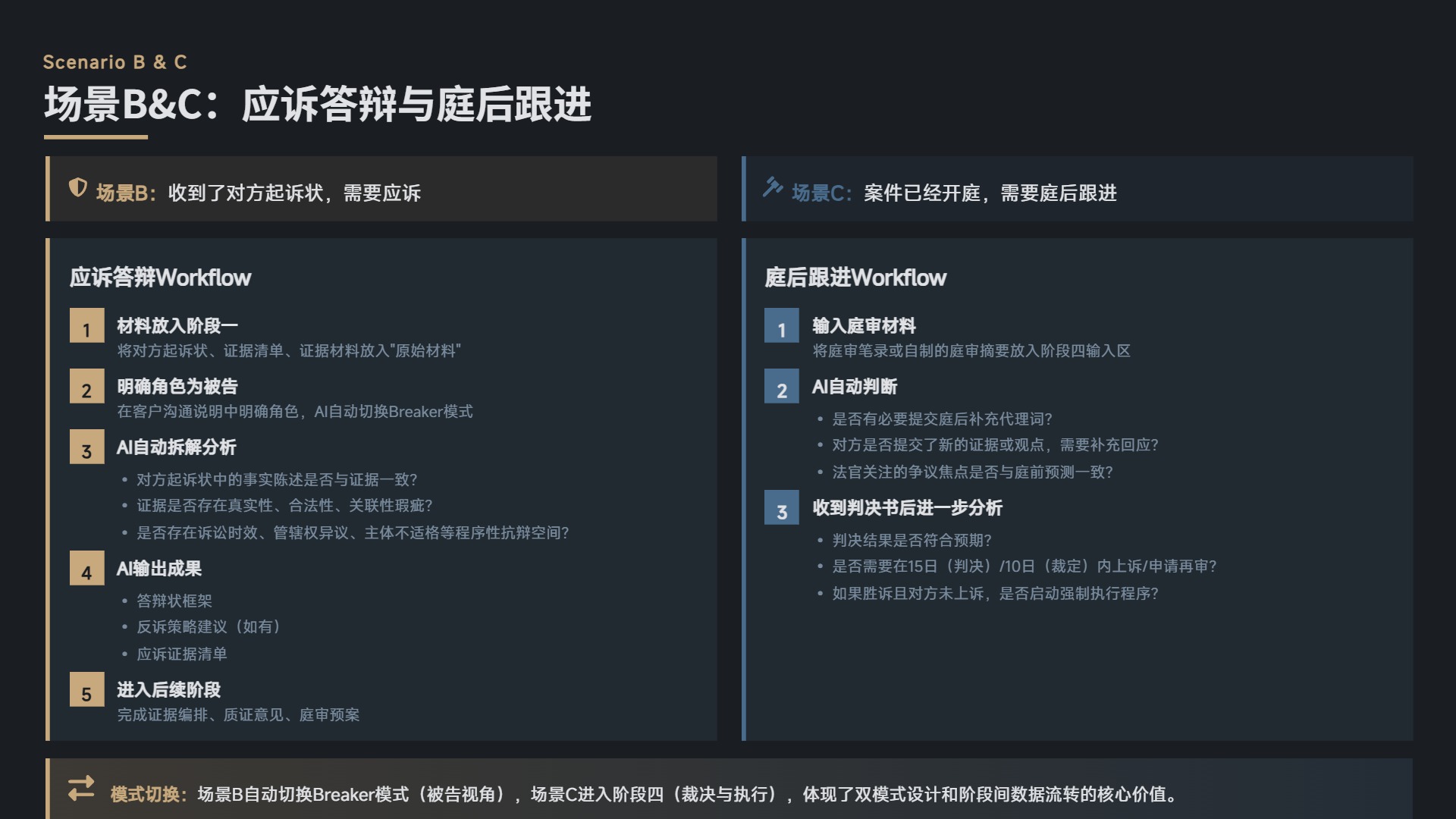
场景 B:收到了对方起诉状,需要应诉
- 将对方起诉状、证据清单、证据材料放入阶段一的”原始材料”。
- 在客户沟通说明中明确角色为”被告”。
- AI 自动切换为 Breaker 模式,侧重拆解对方的事实漏洞和证据瑕疵:
- 对方起诉状中的事实陈述是否与证据一致?
- 证据是否存在真实性、合法性、关联性瑕疵?
- 是否存在诉讼时效、管辖权异议、主体不适格等程序性抗辩空间?
- 输出答辩状框架、反诉策略建议(如有)、应诉证据清单。
- 进入后续阶段,完成证据编排、质证意见、庭审预案。
场景 C:案件已经开庭,需要庭后跟进
- 将庭审笔录或自制的庭审摘要放入阶段四的输入区。
- AI 根据庭审情况自动判断:
- 是否有必要提交庭后补充代理词?
- 对方在庭审中是否提交了新的证据或观点,需要补充回应?
- 法官关注的争议焦点是否与庭前预测一致?
- 若收到判决书,AI 进一步分析:
- 判决结果是否符合预期?
- 是否需要在 15 日(判决)/10 日(裁定)内上诉/申请再审?
- 如果胜诉且对方未上诉,是否启动强制执行程序?
六、谁适合用这个项目?

本项目的适用人群,比我最初预想的要广。
| 人群 | 使用方式 | 核心价值 |
|---|---|---|
| 任何诉讼参与方 | 根据自身角色选择对应模块 | 了解自己的案件处于什么阶段,接下来会发生什么,需要准备什么 |
| 独立执业律师 | 全套使用 | 标准化办案流程,减少低级错误,提高效率 |
| 团队/律所 | 作为团队知识库底稿 | 统一团队输出标准,降低新人培训成本 |
| 实习律师/律师助理 | 学习为主,辅助使用 | 快速建立”完整诉讼流程”的认知框架 |
| 企业法务 | 了解阶段二、三 | 更好地管理外部律师,评估案件进展和风险 |
| 当事人/自诉人 | 作为知识地图 | 在与律师沟通时知道该问什么、该提供什么、案件到了哪一步 |
| 法学生 | 作为实务预习材料 | 将课本知识与实务操作对接 |
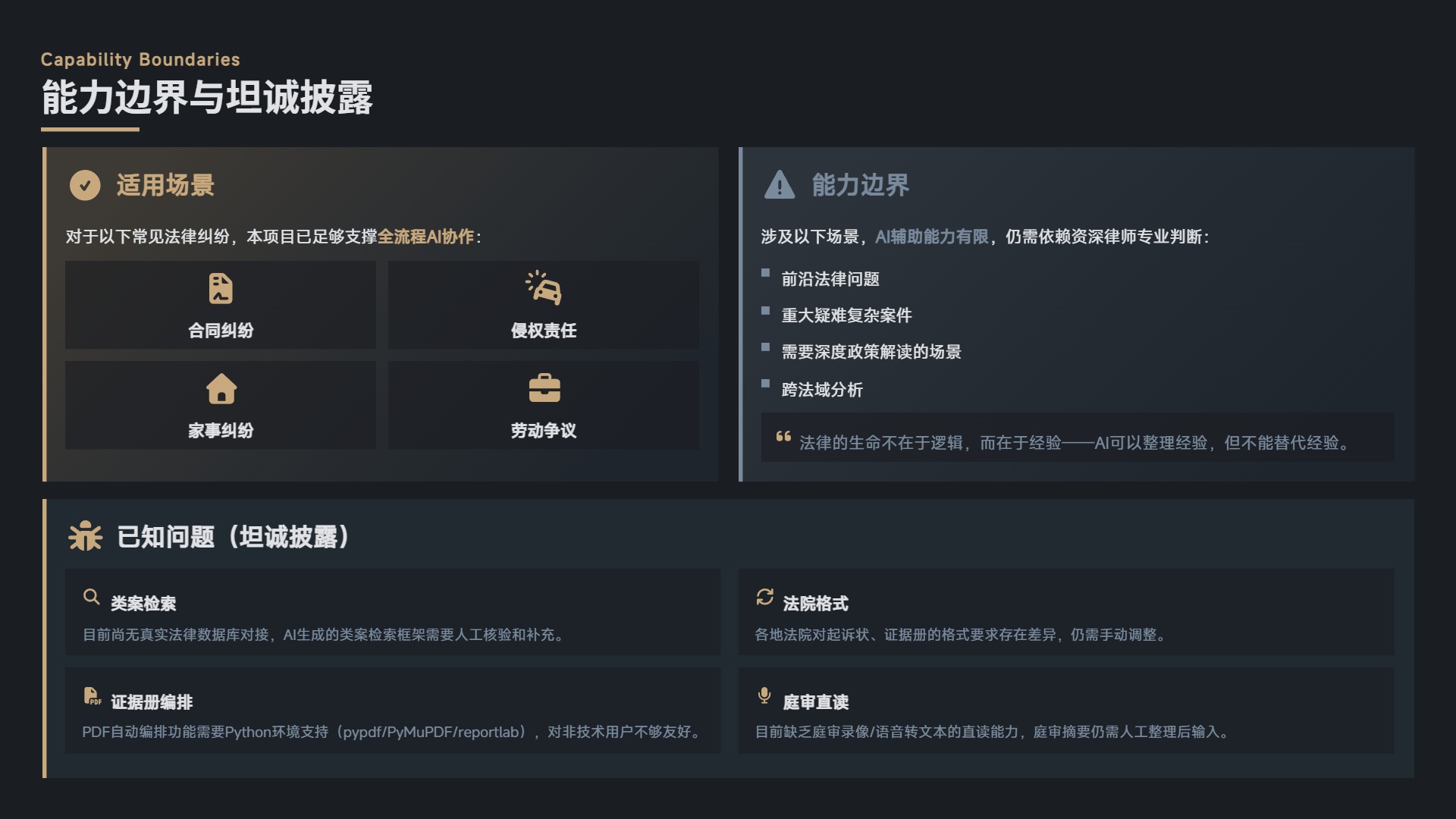
但需要再次强调项目的能力边界:对于合同、侵权、家事、劳动等常见的法律纠纷,本项目已足够支撑全流程的 AI 协作;涉及前沿法律问题、重大疑难复杂案件、需要深度政策解读或跨法域分析的场景,AI 的辅助能力有限,仍需依赖资深律师的专业判断。
这不是谦虚,而是对诉讼实务的尊重。法律的生命不在于逻辑,而在于经验——AI 可以整理经验,但不能替代经验。
七、当前状态、模拟测试与路线图
当前版本:Alpha v0.1.0
四阶段框架已搭建完成,22 份参考模板、4 套 SKILL.md 初稿已完成并经过模拟案例测试。
模拟案例测试说明
如前所述,本项目的每一套 SKILL.md 在定稿前都经过了模拟案例测试。测试方法如下:
- 为每个阶段设计 3~5 个不同类型的虚拟案件(合同、侵权、借贷、家事等);
- 用 AI 生成逼真的原始材料(包括合同文本、微信聊天记录、银行流水、照片等);
- 将材料输入 SKILL.md,检验 AI 的输出是否符合格式要求、逻辑是否自洽、是否遗漏关键信息;
- 不通过的指令回退重写,直至通过。
这个测试过程本身也很有意思——它让我发现了很多”人脑觉得理所当然、但 AI 完全get不到”的隐性假设。例如,人类律师看到一份合同就知道”签约主体 = 原被告候选人”,但 AI 不会自动建立这个关联,除非你在 SKILL.md 里显式写明。
已知问题
- 类案检索:目前尚无真实法律数据库对接,AI 生成的类案检索框架需要人工核验和补充。
- 证据册编排:PDF 自动编排功能需要 Python 环境支持(pypdf / PyMuPDF / reportlab),对非技术用户不够友好。
- 法院格式:各地法院对起诉状、证据册的格式要求存在差异,仍需手动调整。
- 庭审直读:目前缺乏庭审录像/语音转文本的直读能力,庭审摘要仍需人工整理后输入。
后续规划
- 收集真实使用反馈,持续优化阶段模板和 SKILL.md 指令
- 增加专项模块(劳动争议、知识产权、建设工程、公司股权等)
- 探索与法律数据库 API 的对接,提升类案检索和法条引用的准确性
- 增加可视化流程图和检查清单,降低非律师用户的使用门槛
八、结语
回到文章开头的那个比喻。
如果你对一个机器人说”去厨房给我拿一杯水”,它可能会失败。但如果你把任务切分成清晰的步骤,给它一张厨房的地图、一个杯子的图例、一个水龙头的位置标记,它成功的概率就会大幅提升。
法律 AI 的当下困境,不是 AI 不够聪明,而是我们还没有把”打官司”这件事切分成足够清晰的步骤。 本项目的意义,不在于让 AI 替代律师思考,而在于把律师从重复性的信息整理和格式规范化工作中解放出来,把精力集中在真正需要专业判断的地方——策略选择、庭审应变、利益权衡、客户沟通。
我把民事诉讼律师蒸馏了,蒸馏出的不是律师的替代者,而是一套让律师更高效、更规范、更少犯错的协作框架。
项目采用 MIT License 开源,GitHub 地址:https://github.com/LyronLee/Civil-and-commercial-litigation-lawyer.md
如果你有兴趣试用、反馈、共建,欢迎通过上述链接提交 Issue 或 Pull Request,也可以直接联系我。
免责声明:本项目及 AI 生成的所有内容仅供辅助参考,不构成正式法律意见。任何拟提交法院的文件,须经具备执业资格的专业人士审核、修改、签章后方可使用。使用本项目产生的任何法律后果,由使用者自行承担。